Projects configuration and Settings#
Jobflow-remote allows to handle multiple configurations, defined projects. Since for most of the users a single project is enough let us first consider the configuration of a single project. The handling of Multiple Projects will be described below.
Aside from the project options, a set of General Settings - Environment variables can be also be configured through environment variables or an additional configuration file.
Warning
As this is a common source of error, it is important to note that the jobflow-remote
Runner reads all the configurations when the processes is started and does
not attempt to refresh them during the execution. Whenever any configuration is changed
the Runner should be restarted.
Project options#
The project configurations allow to control the behaviour of the Job execution, as well as the other objects in jobflow-remote. Here a full description of the project’s configuration file will be given. If you are looking for a minimal example with its description you can find it in the Configuration section.
The specifications of the project’s attributes are given by the Project pydantic
model, that serves the purpose of parsing and validating the configuration files, as
well as giving access to the associated objects (e.g. the JobStore).
A graphical representation of the Project model and thus of the options available
in the configuration file is given below (generated with erdantic)
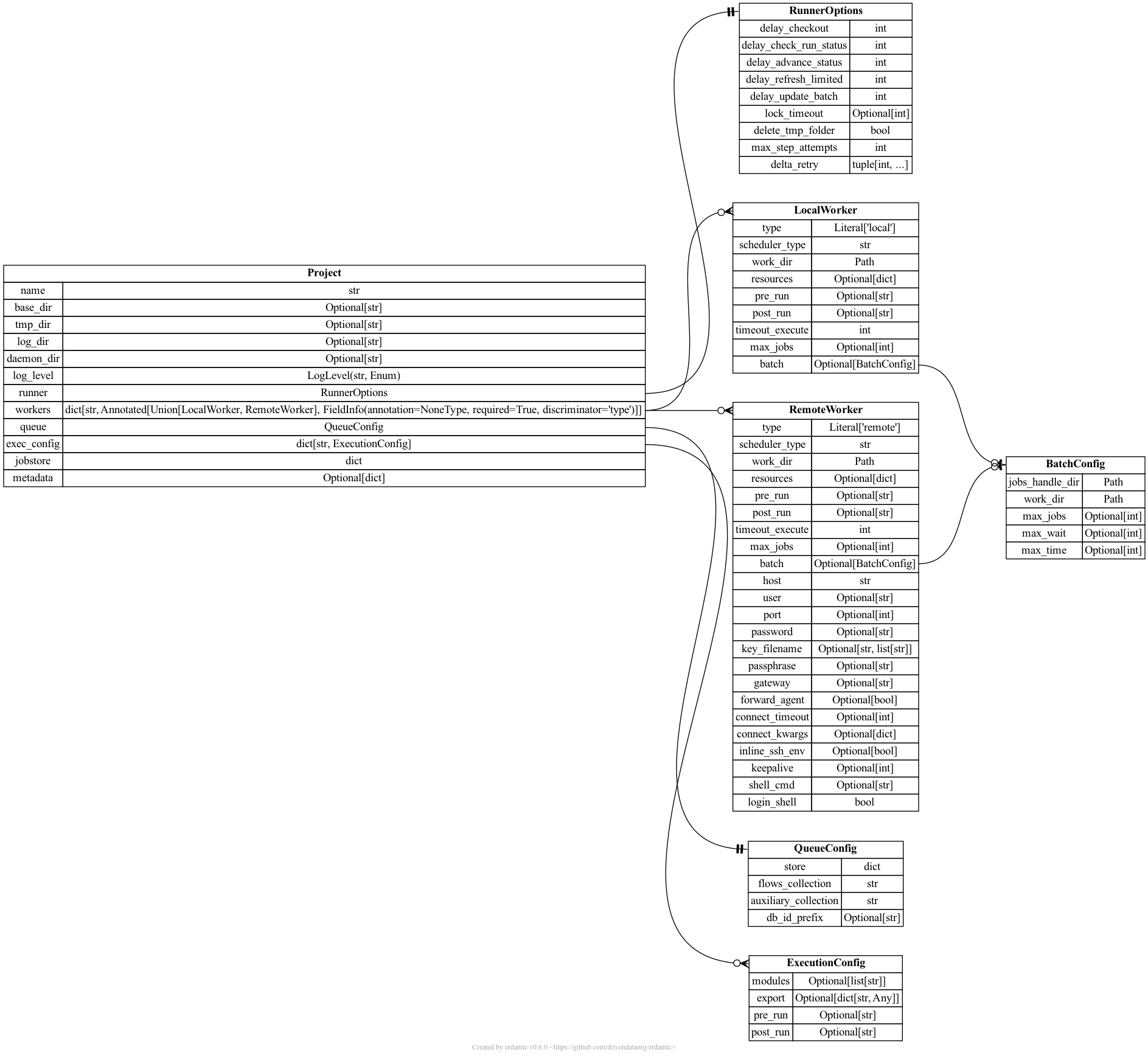
A description for all the types and keys of the project file is given in the Project specs section below, while an example for a full configuration file can be generated running:
jf project generate --full YOUR_PROJECT_NAME
Note that, while the default file format is YAML, JSON and TOML are also acceptable format.
You can generate the example in the other formats using the --format option.
Note
In case of failed validation of any of the configuration options, the file will not be recognized as a project at all. To check the errors in the validation the easiest option is to run:
jf project list --warn
Warning
Some configuration options should not be shared among different projects. For example, sharing the same queue store between two different projects will result in unpredictable behaviour. The following command checks the presence of potentially problematic collisions among different projects:
jf project check-conflicts
Name and folders#
The project name is given by the name attribute. The name will be used to create
a subfolder containing
files with the parsed outputs copied from the remote workers
logs
files used by the daemon
For all these folders the paths are set with defaults, but can be customised setting
tmp_dir, log_dir and daemon_dir.
Warning
The project name does not take into consideration the configuration file name. For coherence it would be better to use the project name as file name.
Example
Standard usage will not require filling in all directories path and usually just the name can be provided in the configuration:
name: my_project
Workers#
Multiple workers can be defined in a project. In the configuration file they are given with their name as keyword, and their properties in the contained dictionary.
Several defining properties should be set in the configuration of each workers.
First it should be specified the type. At the moment the possible worker types are
local: a worker running on the same system as theRunner. No connection is needed for theRunnerto reach the queueing system.remote: a worker on a different machine than theRunner, requiring an SSH connection to reach it.
Since the Runner needs to constantly interact with the workers, for the latter
type all the credentials to connect automatically should be provided. The best option
would be to set up a passwordless connection and define it in the ~/.ssh/config
file.
The other key property of the workers is the scheduler_type. It can be any of the
values supported by the qtoolkit. Typical
values are:
shell: the Job is executed directly in the shell. No queue will be used. If not limited, all the Jobs can be executed simultaneouslyslurm,pbs, …: the name of a queueing system. The job will be submitted to the queue with the selected resources.
Another mandatory argument is work_dir, indicating the full path for a folder
on the worker machine where the Jobs will be actually executed.
It is possible to optionally select default values for keywords like pre_run
and resources, that can be overridden for individual Jobs. Note that these
configurations will be applied to all the Jobs executed by the worker. These
are thus more suitable for generic settings (e.g. the activation of a python
environment, or loading of some modules), rather than for the specific code
configurations. Those can better be set with the Execution configurations.
Note
If a single worker is defined it will be used as default in the submission of new Flows.
Warning
By default, jobflow-remote fetches the status of the jobs from the scheduler by
passing the list of ids. If the selected scheduler does not support this option
(e.g. SGE), it is also necessary to specify the username on the worker machine
through the scheduler_username option. Jobflow-remote will use that as a filter,
instead of the list of ids.
Example
Several workers of different kinds can be defined:
workers:
my_cluster_front_end: # A worker on the front end of the cluster
scheduler_type: shell
work_dir: /path/to/run/dir
# Activate the conda environment on the worker
pre_run: "\neval \"$(conda shell.bash hook)\"\nconda activate jfr\n"
type: remote
# No connection details if they are defined in the ~/.ssh/config file
host: my_cluster
my_cluster: # same cluter, a worker using the SLURM queue
scheduler_type: slurm
work_dir: /path/to/run/dir
resources:
pre_run: "\neval \"$(conda shell.bash hook)\"\nconda activate jfr\n"
type: remote
host: my_cluster
another_cluster: # A remote worker on another cluster
scheduler_type: slurm
work_dir: /path/to/another/run/dir
pre_run: source /data/venv/jobflow/bin/activate
type: remote
# also possible to define connection details here
host: another.cluster.host.net
user: username
key_filename: /path/to/ssh/private/key
another_cluster_batch: # A batch worker on the second cluster
scheduler_type: slurm
work_dir: /path/to/another/run/dir
# Each batch job will run on two nodes with 24 cores each
resources:
nodes: 2
ntasks_per_node: 24
mem: 95000
partition: xxx
pre_run: source /data/venv/jobflow/bin/activate
type: remote
host: another.cluster.host.net
user: username
key_filename: /path/to/ssh/private/key
# maximum 5 batch Slurm jobs in the queue at the same time
max_jobs: 5
# This will determine that the worker is a "batch" worker
batch:
jobs_handle_dir: /some/remote/path/run/batch_handle_slurm
work_dir: /some/remote/path/run/batch_work_slurm
# two jobflow Job executed in parallel in a single SLURM submission
parallel_jobs: 2
local_shell: # A local worker running in the shell
scheduler_type: shell
work_dir: /local/path/to/run/jobs
pre_run: "\neval \"$(conda shell.bash hook)\"\nconda activate atomate2_pyd2\n"
type: local
# Limit the number of local jobs. Since there is no queue they can all
# start simultaneously otherwise
max_jobs: 3
JobStore#
The jobstore value contains a dictionary representation of the standard
JobStore object defined in jobflow. It can either be the serialized
version as obtained by the as_dict module or the representation defined
in jobflow’s documentation.
This JobStore will be used to store the outputs of all the Jobs executed
in this project.
Note
The JobStore should be defined in jobflow-remote’s configuration file.
The content of the standard jobflow configuration file will be ignored.
Warning
If you have been using jobflow without jobflow-remote and you have a
JobStore defined in a jobflow.yaml it will be ignored. Only the
definition in the jobflow-remote configuration file will be considered
Example
Define a JobStore similarly to standard jobflow
jobstore:
docs_store:
type: MongoStore
host: <host name>
port: 27017
username: <username>
password: <password>
database: <database name>
collection_name: outputs
Note
For compatibility with the original jobflow configuration file, the field can
also be defined as JOB_STORE instead of ``jobstore`.
Queue Store#
The queue element contains the definition of the database containing the
state of the Jobs and Flows. The subelement store should contain the
representation of a maggma Store.
As for the JobStore it can be either its serialization or the same kind
of representation used for the docs_store in jobflow’s configuration file.
The main collection defined by the Store will contain the information about the
state of the Jobs. In addition to this Jobs collection, jobflow-remote also relies on several
other collections within the same database to manage and track different aspects of the system:
Flows collection: keeps track of the state of Flows and their relationship to Jobs.
Auxiliary collection: stores additional internal metadata required by jobflow-remote.
Batches collection: stores information about batch processes (see Batch submission), including their state, associated worker, start and end times, and the list of Jobs executed within each batch. This collection allows for monitoring both active and past batch executions.
The names of these collections can be customized in the configuration file.
Warning
The queue Store should be a subclass of the MongoStore and currently
it should be based on a real MongoDB (e.g. not a JSONStore).
Some key operations required by jobflow-remote on the collections are not
supported by any file-based MongoDB implementation at the moment.
Warning
If the JobStore is also based on a MongoDB, it is often convenient to have
its main docs_store in the same database as the queue store. In that
case it is important that the two do not point to the same collection.
Unexpected errors may happen otherwise.
Example
Define a queue store as maggma store. It is possible to use the same syntax
as for the JobStore. Customizing the names of the additional collections
is also possible but not necessary.
queue:
store:
type: MongoStore
host: <host name>
port: 27017
username: <username>
password: <password>
database: <database name>
collection_name: jobs
flows_collection: flows
auxiliary_collection: jf_auxiliary
batches_collection: jf_batches
Execution configurations#
It is possible to define a set of ExecutionConfig objects to quickly set up
configurations for different kind of Jobs and Flow. The exec_config key
contains a dictionary where the keys are the names associated to the configurations
and for each a set of instruction to be set before and after the execution of the Job.
See the Execution configuration section for more details and a usage examples.
Example
Multiple configurations can be defined, for example one for each version of an
external code or for different software requirements. If multiple workers
are present, different exec_config will need to be defined for each of them.
exec_config:
xxx_v1_1_my_cluster:
modules:
- releases/2021b
- intel/2021b
export:
PATH: /path/to/executable/v1.1:$PATH
pre_run:
post_run:
xxx_v3_2_my_cluster:
modules:
- releases/2023b
- intel/2023b
export:
PATH: /path/to/executable/v3.2:$PATH
yyy_local:
export:
PATH: /path/to/local/executable:$PATH
pre_run: "echo 'test'\necho 'test2'"
Runner options#
The behaviour of the Runner can also be customized to some extent. In particular
the Runner implements an exponential backoff mechanism for retrying when an
operation of updating of a Job state fails. The amount of tries and the delay between
them can be set max_step_attempts and delta_retry values. In addition some
reasonable values are set for the delay between each check of the database for
different kind of actions performed by the Runner. These intervals can be
changed to better fit your needs. Remind that reducing these intervals too much
may put unnecessary strain on the database.
Example
Most of the times default values should be fine. Here is how to customize the Runner execution
runner:
delay_checkout: 10
delay_check_run_status: 10
delay_advance_status: 10
delay_update_batch: 10
lock_timeout: 86400
delete_tmp_folder: true
max_step_attempts: 3
delta_retry:
- 30
- 300
- 1200
Metadata#
While this does currently not play any role in the execution of jobflow-remote, this can be used to include some additional information to be used by external tools or to quickly distinguish a configuration file among others.
Multiple Projects#
While a single project can be enough for most of the users and for beginners,
it may be convenient to define different databases, configurations and python
environments to work on different topics. For this reason jobflow-remote will
consider as potential projects configuration all the YAML, JSON and TOML files
in the ~/.jfremote folder. There is no additional procedure required to
add or remove project, aside from creating/deleting a project configuration file.
Warning
Different projects are meant to use different Queue Stores. Sharing the same collections for two projects is not a supported option.
To define the Queue Store for multiple projects two options are available:
each project has its own database, with standard collection names
a single database is used and each project is assigned a set of collections. For example, a configuration for one of the projects could be:
queue: store: type: MongoStore database: DB_NAME collection_name: jobs_project1 ... flows_collection: flows_project1 auxiliary_collection: jf_auxiliary_project1
And the same for a second project with different collection names.
There is no constraint for the database and collection used for the output
JobStore. Even though it may make sense to separate the
sets of outputs, it is possible to share the same collection among multiple
projects. In that case the output documents will have duplicated db_id,
as each project has its own counter. If this may be an issue it is possible
to set different db_id_prefix values in the queue configuration for
the different projects.
If more than one project is present and a specific one is not selected, the
code will always stop asking for a project to be specified. Python functions
like submit_flow and get_jobstore accept a project argument to
specify which project should be considered. For the command line interface
a general -p allows to select a project for the command that is being
executed:
jf -p another_project job list
To define a default project for all the functions and commands executed on the system or in a specific cell see the General Settings - Environment variables section.
Project specs#
Project
Type: objectThe configurations of a Project.
No Additional PropertiesName
Type: stringThe name of the project
Base Dir
Default: nullThe base directory containing the project related files. Default is a folder with the project name inside the projects folder
Tmp Dir
Default: nullFolder where remote files are copied. Default a 'tmp' folder in base_dir
Log Dir
Default: nullFolder containing all the logs. Default a 'log' folder in base_dir
Daemon Dir
Default: nullFolder containing daemon related files. Default to a 'daemon' folder in base_dir
LogLevel
Type: enum (of string) Default: "info"The level set for logging
Must be one of:
- "error"
- "warn"
- "info"
- "debug"
RunnerOptions
Type: objectThe options for the Runner
No Additional PropertiesDelay Checkout
Type: number Default: 30Delay between subsequent execution of the checkout from database (seconds)
Delay Check Run Status
Type: number Default: 30Delay between subsequent execution of the checking the status of jobs that are submitted to the scheduler (seconds)
Delay Advance Status
Type: number Default: 30Delay between subsequent advancement of the job's remote state (seconds)
Delay Refresh Limited
Type: number Default: 600Delay between subsequent refresh from the DB of the number of submitted and running jobs (seconds). Only used if a worker with max_jobs is present
Delay Update Batch
Type: number Default: 60Delay between subsequent refresh from the DB of the number of submitted and running jobs (seconds). Only used if a batch worker is present
Delay Ping Db
Type: number Default: 3600Delay between subsequent pings to the running runner document.
Lock Timeout
Default: 86400Time to consider the lock on a document expired and can be overridden (seconds)
Delete Tmp Folder
Type: boolean Default: trueWhether to delete the local temporary folder after a job has completed
Max Step Attempts
Type: integer Default: 3Maximum number of attempt performed before failing an advancement of a remote state
Delta Retry
Type: array of number Default: [30, 300, 1200]List of increasing delay between subsequent attempts when the advancement of a remote step fails
No Additional ItemsEach item of this array must be:
Workers
Type: objectA dictionary with the worker name as keys and the worker configuration as values
Each additional property must conform to the following schema
LocalWorker
Type: objectWorker representing the local host.
Executes command directly.
No Additional PropertiesType
Type: const Default: "local"The discriminator field to determine the worker type
Specific value:"local"
Scheduler Type
Type of the scheduler. Either a string depending on the values supported by QToolKit or a serialized representation of a (subclass of) BaseSchedulerIO
Additional Properties of any type are allowed.
Type: objectWork Dir
Type: stringFormat: pathAbsolute path of the directory of the worker where subfolders for executing the calculation will be created
Resources
Default: nullA dictionary defining the default resources requested to the scheduler. Used to fill in the QToolKit template
Additional Properties of any type are allowed.
Type: objectPre Run
Default: nullString with commands that will be executed before the execution of the Job
Post Run
Default: nullString with commands that will be executed after the execution of the Job
Execution Cmd
Default: nullString with commands to execute the Job on the worker. By default will be set to jf -fe execution run {}. The {} part will be used to insert the path to the execution directory and it is mandatory. Change only for specific needs (e.g. thejf command needs to be executed in a container).
Timeout Execute
Type: integer Default: 60Timeout for the execution of the commands in the worker (e.g. submitting a job)
Max Jobs
Default: nullThe maximum number of jobs that can be submitted to the queue.
Value must be greater or equal to 0
Options for batch execution. If define the worker will be considered a batch worker
BatchConfig
Type: objectConfiguration for execution of batch jobs.
Allows to execute multiple Jobs in a single process executed on the
worker (e.g. SLURM job).
Jobs Handle Dir
Type: stringFormat: pathAbsolute path to a folder that will be used to store information to share with the jobs being executed
Work Dir
Type: stringFormat: pathAbsolute path to a folder where the batch jobs will be executed. This refers to the jobs submittedto the queue. Jobflow's Job will still be executed in the standard folders.
Max Jobs Per Batch
Default: nullMaximum number of jobs executed in a single batch process
Max Wait
Default: 60Maximum time to wait before stopping if no new jobs are available to run (seconds)
Max Time
Default: nullMaximum time after which a job will not start more jobs (seconds). To help avoid hitting the walltime
Parallel Jobs
Default: nullNumber of jobs executed in parallel in the same process
Sleep Time
Default: nullSleep time when no submitted job is available to run before checking again (seconds)
Scheduler Username
Default: nullIf defined, the list of jobs running on the worker will be fetched based on theusername instead that from the list of job ids. May be necessary for some scheduler_type (e.g. SGE)
Sanitize Command
Type: boolean Default: falseSanitize the output of commands in case of failures due to spurious text producedby the worker shell.
Delay Download
Default: nullAmount of seconds to wait to start the download after the Runner marked a Job as RUN_FINISHED. To account for delays in the writing of the file on the worker file system (e.g. NFS).
RemoteWorker
Type: objectWorker representing a remote host reached through an SSH connection.
Uses a Fabric Connection. Check Fabric documentation for more details on the
options defining a Connection.
Type
Type: const Default: "remote"The discriminator field to determine the worker type
Specific value:"remote"
Scheduler Type
Type of the scheduler. Either a string depending on the values supported by QToolKit or a serialized representation of a (subclass of) BaseSchedulerIO
Additional Properties of any type are allowed.
Type: objectWork Dir
Type: stringFormat: pathAbsolute path of the directory of the worker where subfolders for executing the calculation will be created
Resources
Default: nullA dictionary defining the default resources requested to the scheduler. Used to fill in the QToolKit template
Additional Properties of any type are allowed.
Type: objectPre Run
Default: nullString with commands that will be executed before the execution of the Job
Post Run
Default: nullString with commands that will be executed after the execution of the Job
Execution Cmd
Default: nullString with commands to execute the Job on the worker. By default will be set to jf -fe execution run {}. The {} part will be used to insert the path to the execution directory and it is mandatory. Change only for specific needs (e.g. thejf command needs to be executed in a container).
Timeout Execute
Type: integer Default: 60Timeout for the execution of the commands in the worker (e.g. submitting a job)
Max Jobs
Default: nullThe maximum number of jobs that can be submitted to the queue.
Value must be greater or equal to 0
Options for batch execution. If define the worker will be considered a batch worker
BatchConfig
Type: objectConfiguration for execution of batch jobs.
Allows to execute multiple Jobs in a single process executed on the
worker (e.g. SLURM job).
Scheduler Username
Default: nullIf defined, the list of jobs running on the worker will be fetched based on theusername instead that from the list of job ids. May be necessary for some scheduler_type (e.g. SGE)
Sanitize Command
Type: boolean Default: falseSanitize the output of commands in case of failures due to spurious text producedby the worker shell.
Delay Download
Default: nullAmount of seconds to wait to start the download after the Runner marked a Job as RUN_FINISHED. To account for delays in the writing of the file on the worker file system (e.g. NFS).
Host
Type: stringThe host to which to connect
User
Default: nullLogin username
Port
Default: nullPort number
Password
Default: nullLogin password
Key Filename
Default: nullThe filename, or list of filenames, of optional private key(s) and/or certs to try for authentication
No Additional Items
Each item of this array must be:
Passphrase
Default: nullPassphrase used for decrypting private keys
Gateway
Default: nullA shell command string to use as a proxy or gateway
ConnectionData
Type: objectThe representation of a fabric connection.
Mainly used in case of nested gateways.
Host
Type: stringThe host to which to connect
User
Default: nullLogin username
Port
Default: nullPort number
Password
Default: nullLogin password
Key Filename
Default: nullThe filename, or list of filenames, of optional private key(s) and/or certs to try for authentication
No Additional Items
Each item of this array must be:
Passphrase
Default: nullPassphrase used for decrypting private keys
Gateway
Default: nullA shell command string to use as a proxy or gateway
ConnectionData
Type: objectThe representation of a fabric connection.
Mainly used in case of nested gateways.
Connect Kwargs
Default: nullOther keyword arguments passed to paramiko.client.SSHClient.connect
Additional Properties of any type are allowed.
Type: objectForward Agent
Default: nullWhether to enable SSH agent forwarding
Connect Timeout
Default: nullConnection timeout, in seconds
Connect Kwargs
Default: nullOther keyword arguments passed to paramiko.client.SSHClient.connect
Additional Properties of any type are allowed.
Type: objectInline Ssh Env
Default: nullWhether to send environment variables 'inline' as prefixes in front of command strings
Keepalive
Default: 60Keepalive value in seconds passed to paramiko's transport
Shell Cmd
Default: "bash"The shell command used to execute the command remotely. If None the command is executed directly
Login Shell
Type: boolean Default: trueWhether to use a login shell when executing the command
Interactive Login
Type: boolean Default: falseWhether the authentication to the host should be interactive
SeparatedTransferWorker
Type: objectWorker with separate hosts for commands and file transfers.
This is useful for HPC systems where login nodes have SFTP disabled but a
dedicated data transfer node is available (e.g., LRC at LBNL).
Command execution goes through the main host connection, while file operations
(put, get, mkdir, etc.) go through the transfer host.
Type
Type: const Default: "separated_transfer"The discriminator field to determine the worker type
Specific value:"separated_transfer"
Scheduler Type
Type of the scheduler. Either a string depending on the values supported by QToolKit or a serialized representation of a (subclass of) BaseSchedulerIO
Additional Properties of any type are allowed.
Type: objectWork Dir
Type: stringFormat: pathAbsolute path of the directory of the worker where subfolders for executing the calculation will be created
Resources
Default: nullA dictionary defining the default resources requested to the scheduler. Used to fill in the QToolKit template
Additional Properties of any type are allowed.
Type: objectPre Run
Default: nullString with commands that will be executed before the execution of the Job
Post Run
Default: nullString with commands that will be executed after the execution of the Job
Execution Cmd
Default: nullString with commands to execute the Job on the worker. By default will be set to jf -fe execution run {}. The {} part will be used to insert the path to the execution directory and it is mandatory. Change only for specific needs (e.g. thejf command needs to be executed in a container).
Timeout Execute
Type: integer Default: 60Timeout for the execution of the commands in the worker (e.g. submitting a job)
Max Jobs
Default: nullThe maximum number of jobs that can be submitted to the queue.
Value must be greater or equal to 0
Options for batch execution. If define the worker will be considered a batch worker
BatchConfig
Type: objectConfiguration for execution of batch jobs.
Allows to execute multiple Jobs in a single process executed on the
worker (e.g. SLURM job).
Scheduler Username
Default: nullIf defined, the list of jobs running on the worker will be fetched based on theusername instead that from the list of job ids. May be necessary for some scheduler_type (e.g. SGE)
Sanitize Command
Type: boolean Default: falseSanitize the output of commands in case of failures due to spurious text producedby the worker shell.
Delay Download
Default: nullAmount of seconds to wait to start the download after the Runner marked a Job as RUN_FINISHED. To account for delays in the writing of the file on the worker file system (e.g. NFS).
Host
Type: stringThe host to which to connect
User
Default: nullLogin username
Port
Default: nullPort number
Password
Default: nullLogin password
Key Filename
Default: nullThe filename, or list of filenames, of optional private key(s) and/or certs to try for authentication
No Additional Items
Each item of this array must be:
Passphrase
Default: nullPassphrase used for decrypting private keys
Gateway
Default: nullA shell command string to use as a proxy or gateway
ConnectionData
Type: objectThe representation of a fabric connection.
Mainly used in case of nested gateways.
Forward Agent
Default: nullWhether to enable SSH agent forwarding
Connect Timeout
Default: nullConnection timeout, in seconds
Connect Kwargs
Default: nullOther keyword arguments passed to paramiko.client.SSHClient.connect
Additional Properties of any type are allowed.
Type: objectInline Ssh Env
Default: nullWhether to send environment variables 'inline' as prefixes in front of command strings
Keepalive
Default: 60Keepalive value in seconds passed to paramiko's transport
Shell Cmd
Default: "bash"The shell command used to execute the command remotely. If None the command is executed directly
Login Shell
Type: boolean Default: trueWhether to use a login shell when executing the command
Interactive Login
Type: boolean Default: falseWhether the authentication to the host should be interactive
ConnectionData
Type: objectConnection data for the file transfer host. Use this when the main host has SFTP disabled but a dedicated transfer node is available. File operations (put/get) will use this connection while commands use the main host.
Same definition as ConnectionDataQueueConfig
Type: objectThe configuration of the Store used to store the states of the Jobs and the Flows
No Additional PropertiesStore
Type: objectDictionary describing a maggma Store used for the queue data. Can contain the monty serialized dictionary or a dictionary with a 'type' specifying the Store subclass. Should be subclass of a MongoStore, as it requires to perform MongoDB actions. The collection is used to store the jobs
Additional Properties of any type are allowed.
Type: objectFlows Collection
Type: string Default: "flows"The name of the collection containing information about the flows. Taken from the same database as the one defined in the store
Auxiliary Collection
Type: string Default: "jf_auxiliary"The name of the collection containing auxiliary information. Taken from the same database as the one defined in the store
Batches Collection
Type: string Default: "batches"The name of the collection containing batches information. Taken from the same database as the one defined in the store
Db Id Prefix
Default: nulla string defining the prefix added to the integer ID associated to each Job in the database
Exec Config
Type: objectA dictionary with the ExecutionConfig name as keys and the ExecutionConfig configuration as values
Each additional property must conform to the following schema
ExecutionConfig
Type: objectConfiguration to be set before and after the execution of a Job.
No Additional PropertiesModules
Default: nulllist of modules to be loaded
No Additional Items
Each item of this array must be:
Export
Default: nulldictionary with variable to be exported
Additional Properties of any type are allowed.
Type: objectPre Run
Default: nullOther commands to be executed before the execution of a job
Post Run
Default: nullCommands to be executed after the execution of a job
Jobstore
Type: objectThe JobStore used for the output. Can contain the monty serialized dictionary or the Store in the Jobflow format
Additional Properties of any type are allowed.
Type: objectRemote Jobstore
Default: nullThe JobStore used for the data transfer between the Runnerand the workers. Can be a string with the standard values
Additional Properties of any type are allowed.
Type: objectMetadata
Default: nullA dictionary with metadata associated to the project
Additional Properties of any type are allowed.
Type: objectOptional Jobstores
A dictionary of optional JobStores that can be use to store outputs instead of the default jobstore. The key is the name used to refer to the JobStore.
Each additional property must conform to the following schema
Type: objectAdditional Properties of any type are allowed.
Type: objectGeneral Settings - Environment variables#
Aside from the project specific configuration, a few options can also be defined in general. There are two ways to set these options:
set the value in the
~/.jfremote.yamlconfiguration file.set an environment variable composed by the name of the variable and prepended by the
JFREMOTE_prefix:export JFREMOTE_PROJECT=project_name
Note
The name of the exported variables is case-insensitive (i.e. jfremote_project is equally valid).
The most useful variable to set is the project one, allowing to select the
default project to be used in a multi-project environment.
Other generic options are the location of the projects folder, instead of
~/.jfremote (JFREMOTE_PROJECTS_FOLDER) and the path to the ~/.jfremote.yaml
file itself (JFREMOTE_CONFIG_FILE).
Some customization options are also available for the behaviour of the CLI.
For more details see the API documentation jobflow_remote.config.settings.JobflowRemoteSettings.
Here after is the list of possible general settings:
JobflowRemoteSettings
Type: objectNo Additional Properties
Config File
Type: string Default: "/home/runner/.jfremote.yaml"Location of the config file for jobflow remote.
Projects Folder
Type: string Default: "/home/runner/.jfremote"Location of the projects files.
Project
Default: nullThe name of the project used.
Cli Full Exc
Type: boolean Default: falseIf True prints the full stack trace of the exception when raised in the CLI.
Cli Suggestions
Type: boolean Default: trueIf True prints some suggestions in the CLI commands.
LogLevel
Type: enum (of string) Default: "warn"The level set for logging in the CLI
Must be one of:
- "error"
- "warn"
- "info"
- "debug"
Cli Job List Columns
Default: nullThe list of columns to show in the jf job list command. For available options check the corresponding help: jf job list -h.
No Additional Items
Each item of this array must be:
Cli Load Plugins
Type: boolean Default: trueIf False the CLI plugins will not be loaded.